Stop putting everything in CLAUDE.md
The stakes
At my day job, we build trunk-level communication satellites for countries like Taiwan (whose undersea fiber optic cables keep getting cut by the PRC), so minimizing unpredictability in our systems is exceptionally important.
In that role, I noticed over and over again that Claude Code would ignore CLAUDE.md instructions, and that it responded much better to agent skills.
The observation
This experience contrasts with Anthropic’s documentation and marketing materials, wherein Anthropic tells people to put instructions for Claude Code in a CLAUDE.md file. For example, it was a key focus on 24 March in a webinar called Claude Code Advanced Patterns, and it’s front and center in Best Practices for Claude Code from their official docs.
Moreover, I had a major concern: there’s no simple way to utilize test-driven development (TDD) on CLAUDE.md files — and thus no way to verify that any given instruction is adding value.
Agentic TDD resembles hypothesis-driven scientific discovery. One paradigmatic red/green/refactor implementation exists in Jesse Obra’s superpowers plugin: the agent writes the evals (quiz questions for LLMs) it expects to fail, tests them with a clean sub-agent, writes a skill focused on the things the sub-agent got wrong, repeats the test phase but now with the skill introduced, and refactors and repeats the process if gaps remain.
Sometimes the red phase indicates that the question is ill-posed and should be reformulated, or that the skill should be discarded entirely because Claude already knows how to do it.
If we want to add statistical rigor to the testing of our non-deterministic agents, we can run it as a Monte Carlo with parallel sub-agents.
The mystery
So why would Anthropic rely internally on a vibes-based system over one whose behavior is testable and quantifiable? The mystery deepened when the source maps for Claude Code leaked, and it became apparent that there existed yet another strategy — MagicDocs — for providing instructions to Claude. I wondered how best to guide less experienced engineers on which instructions should go where, and whether ideal context placement might depend on the desired outcome.
Relying on the source maps and reverse-engineered Claude Code prompts, and with a lot of talking to rubber ducks, I wrote a five-chapter manual and built an open-source plugin. Then, days into the research, Anthropic removed MagicDocs entirely — validating my hypothesis that the experiment hadn’t worked out and simplifying the decision tree considerably.
The leak and the research
Wavespeed has published an excellent timeline of the Claude Code leak. They write,
No customer data, no API credentials, no model weights. What was exposed: approximately 512,000 lines of TypeScript across ~1,900 files — the query engine, tool system, multi-agent orchestration logic, context compaction, and 44 feature flags covering functionality that’s built but not yet shipped. Those feature flags are the most strategically sensitive part. Compiled code sitting behind flags that evaluate to
falsein the external build isn’t just implementation detail — it’s a product roadmap. Competitors can now see what Anthropic has built and is considering shipping. That strategic surprise can’t be un-leaked.
Within a couple of hours, a Korean developer named Sigrid Jin (handle instructkr) had used OpenAI’s Claude Code competitor, Codex, to do a “clean room” Python rewrite. I don’t know the exact strategy Jin used, but
here's how I'd have done it in a similar timeframe using Superpowers.
1. `/brainstorming` Have Agent One read the TypeScript and write up the design document. 2. Hand off the design document to Agent Two, naive to the original code, and ask it to `/brainstorming` writing a new design document adapting the TypeScript design into Python and Rust. 3. Have Agent One review Agent Two's design and see if Agent Two missed anything. 4. Have Agent Two `/writing-plans` write an implementation plan using `/test-driven-development`, then have an independent reviewer review the plan. 5. Go through and `/writing-skills` on any skill rewrites needed. 6. Use `/subagent-driven-development` to dispatch a team of subagents to implement the plan, with two reviews, one for plan consistency and a second for code quality.I relied on two main sources for my research: Claw Code and a separate set of a couple hundred reverse-engineered prompts Piebald AI automatically pulls from every Claude Code release.
Four mechanisms for user control of behavior
A key take-away from analysis of Claw Code and the prompts is that Claude Code provides four mechanisms for shaping Claude’s behavior: CLAUDE.md, memory, skills, and hooks. Three are prompt-based and non-deterministic, and one (hooks) is purely mechanical and deterministic.

From Claw Code, we know that the system prompt consists of ten segments, shown above. Following the system prompt is the actual conversation. At session start, a <system-reminder> block lists available skills indexed by when_to_use and description — but their full content stays on disk until invoked. At each turn, an additional system reminder provides up to five memory files that a Sonnet subagent has selected based on the memory description field. When a skill is invoked, its content arrives as a tool result — the freshest position in context.
As mentioned, hooks aren’t part of the context. They’re shell commands defined in settings.json that fire at lifecycle events — purely mechanical, no LLM judgment involved:
{
"hooks": {
"PostToolUse": [{
"matcher": "Write|Edit",
"hooks": [{
"type": "command",
"command": "cd $PROJECT_DIR && pnpm lint --fix $FILEPATH"
}]
}]
}
}
Chapter 2 of the Airbender Docs goes into more detail about the mechanization of these different components and how the user-responsive pieces of Claude Code work.
“But how do I decide where to put this instruction?”
It seemed to me that if Claude Code has four different mechanisms for providing mutable instructions to the LLM, users need a way to decide where any given instruction should go. Claude and I arrived at the decision tree through an informal red/green/refactor discussion, where we both tried to produce examples that would falsify our hypotheses. You can read the full analysis, including few-shot examples, in Chapter 4: What to Put Where.
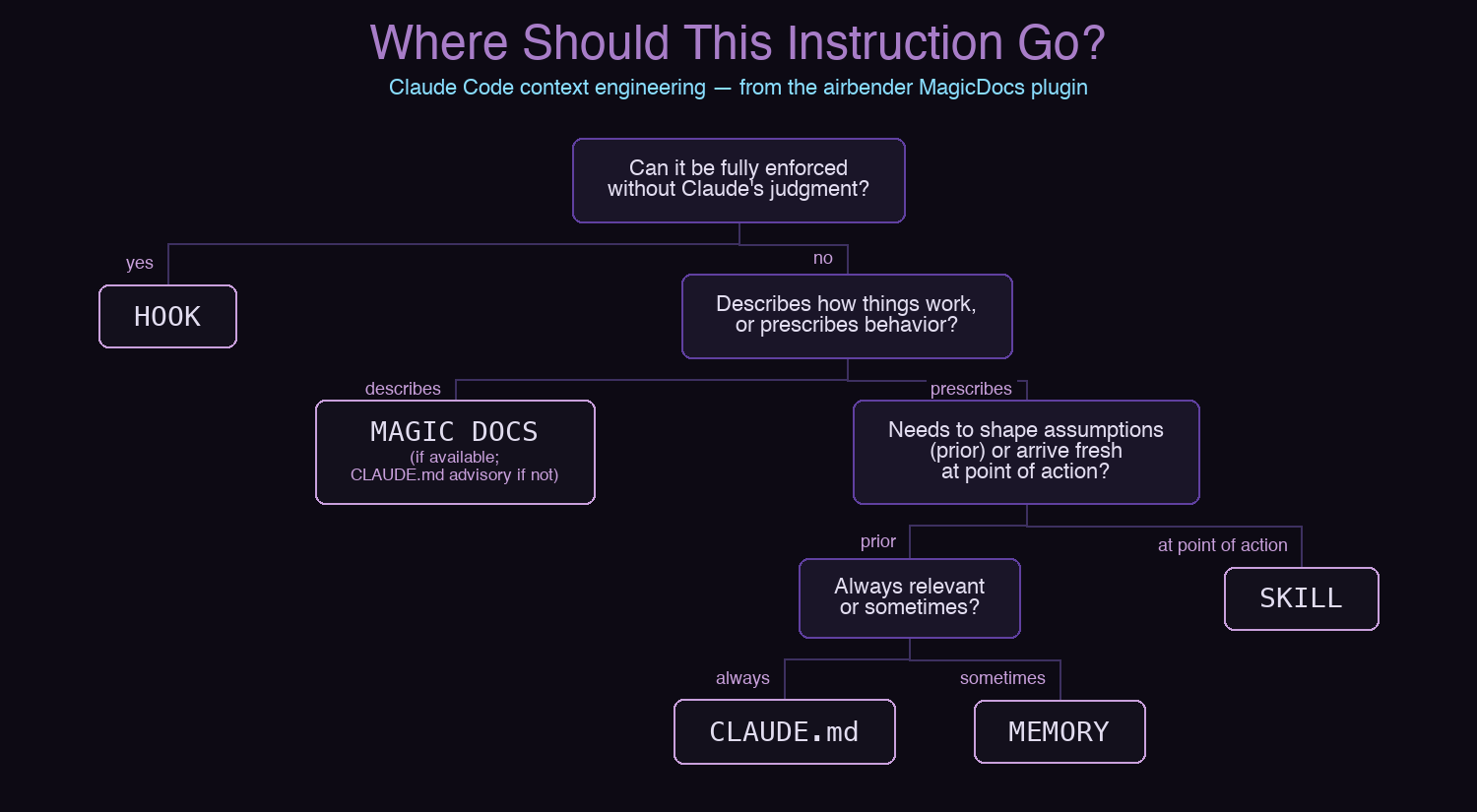
I originally built a skill to mechanize this decision tree, but TDD testing showed the model scores 96% on these classifications without any skill at all — it already knows the difference between a hook and a memory. The red/green/refactor sequence is preserved as a case study in agentic evals.
Building and validating MagicDocs
Without Anthropic’s internal access to Claude Code features, I couldn’t implement MagicDocs exactly as it is in Claude Code, so it became necessary to invent a design that reproduced a MagicDocs analogue without the internal tooling. I asked for a checklist of design questions we would need for this analogue. I also asked Claude to annotate each with the approach Anthropic took, and to order the decisions according to their downstream impact on other design elements.
These design questions left me with doubt. In particular, injecting a note about our MagicDocs into CLAUDE.md seemed a fragile approach, given my earlier claim that instructions often go into that file to die. Moreover, internally, Anthropic runs its MagicDocs agent during “idle cycles” — but what is an idle cycle for someone without unlimited tokens, and could we mimic this behavior with a hook?
I asked Claude to write me two implementation plans — the first to test our design hypothesis in minimum viable product form, and the second for the implementation. Indeed, the MVP revealed a tendency for the MagicDocs subagents to modify or even delete out-of-scope files, which necessitated modifications to the full plan.
Most of the system is encapsulated in a single skill within the airbender plugin, /setup-magicdocs, which:
- Explores the repository structure and identifies a few ways to segment into an initial set of MagicDocs, consulting the user on their preference;
- Creates skeleton docs in
docs/magic/; - Updates
CLAUDE.md; and - Configures the Stop hook to do a pruning pass at session exit.
I also provide a /create-magicdoc skill for adding additional MagicDocs as the repository grows. This partially duplicates /setup-magicdocs, and de-duplicating these is an area for improvement.
The takeaway
No engineer wants their missed CLAUDE.md instruction to show up as the root cause of an anomaly ticket. The solution is to rely on CLAUDE.md as little as possible, and instead to prefer testable instructions.
How might one actually test CLAUDE.md instructions?
With skills, we ask a fresh subagent to try to do something and evaluate its performance against a pre-established set of benchmarks or evals.
With CLAUDE.md, it’s harder. We can test instructions with fresh subagents, which also receive the project’s CLAUDE.md files. However, the issue is often not a fresh sub-agent, but one with its million-token context 93% full. Each iteration of red/green/refactor testing in such an environment is inherently much more expensive than with skills:
| Scenario | Haiku 4.5 | Sonnet 4.6 | Opus 4.6 |
|---|---|---|---|
| Skill TDD (fresh subagent, ~15K tokens) | $0.08 | $0.23 | $0.38 |
CLAUDE.md TDD (fresh conversation, ~12K tokens) |
$0.07 | $0.20 | $0.33 |
CLAUDE.md TDD (93% full context, ~198K tokens) |
$0.62 | $1.87 | $3.12 |
CLAUDE.md TDD (93% full, with prompt caching) |
$0.61 | $1.83 | $3.05 |
This consistency in favoring skill-based instructions is a consequence of where CLAUDE.md tokens versus skill tokens are included in the context, because positional bias in recall is a geometric property of causal transformer architecture. Moreover, as the context window fills, the bias shifts from U-shaped to pure recency — exactly the regime in which skills are favored over an early-context CLAUDE.md instruction.